Ingestion
Ingesting raw data into a data pipeline can be a complex and often error-prone process, with various challenges that can impact the efficiency and reliability of processes downstream that rely on it. Below are some key challenges and potential pitfalls that can happen during this phase of the data pipeline:
-
Incomplete data: Raw data can often contain gaps or missing values, resulting in incomplete records. This can occur due to various reasons like system failures, human input errors, interruptions in data collection processes, and so on. Identifying when data is missing or incomplete is critical at this stage of the data pipeline.
-
Duplicate data: Redundant data records can be ingested, especially in streaming pipelines or systems with unreliable deduplication logic, leading to inflated analytics and inaccurate statistics, ultimately resulting in wrong conclusions and misguided decisions.
-
Schema drift: The structure of the incoming data can sometimes change over time. When the schema drift is drastic, it can lead to downstream issues like failed jobs or corrupted data. However, more subtle changes can go unnoticed, leading to poor decision-making or inaccurate models.
How can GX help solve these problems?
GX gives you the freedom to decide when and how to validate your data. If the raw data has already been ingested to a staging area within your data warehouse, GX can connect directly to it and run Validations to ensure the integrity of the staged raw data. Alternatively, you can create in-memory Data Assets, allowing you to run Validations on your data before it lands in your data warehouse, thereby allowing you to take steps like deduplication and value backfilling.
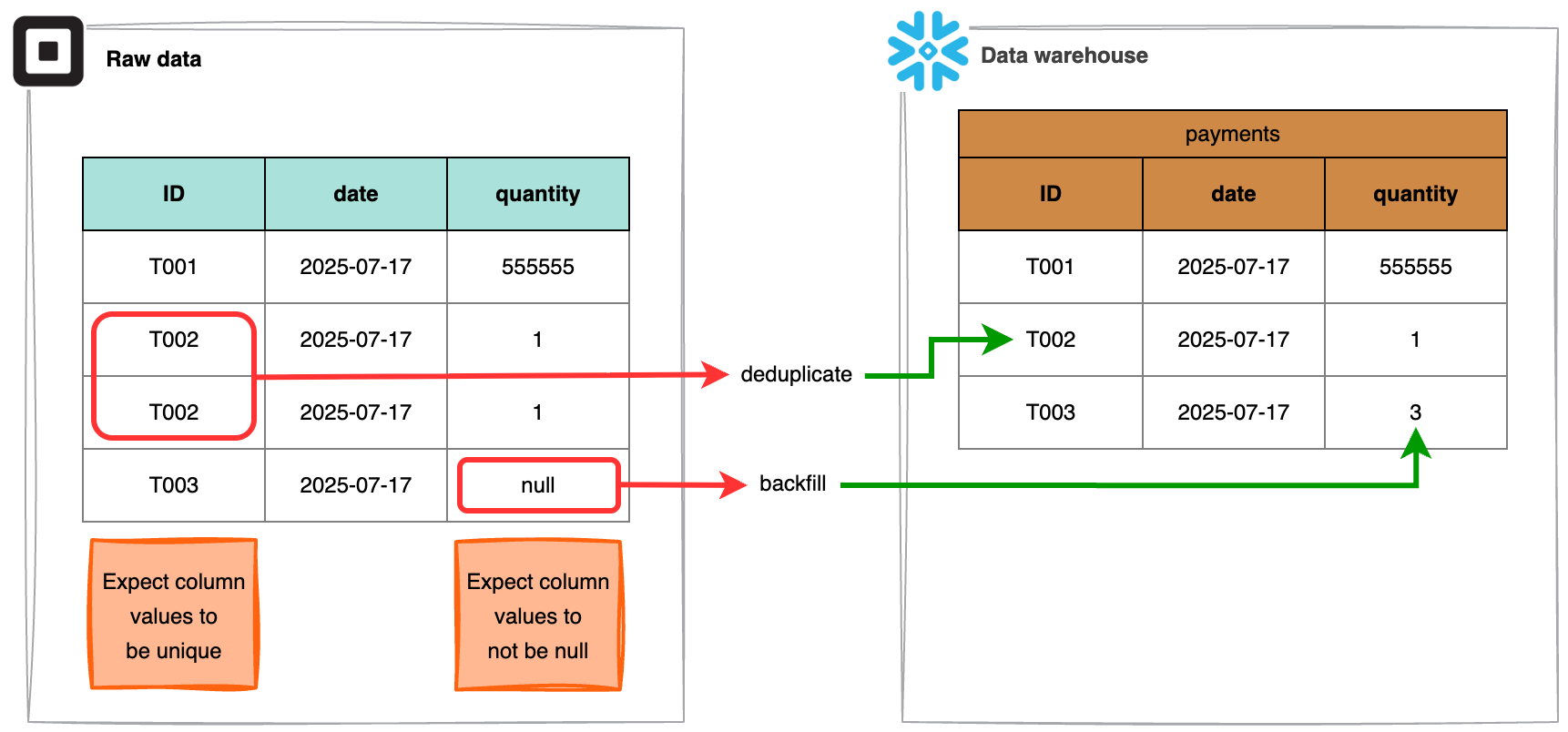
GX offers the ability to trigger validation runs immediately after ingestion is complete, for example by calling GX from your pipeline or orchestrator. This gives you timely feedback on the health of your data and lets you take action to correct errors before they propagate downstream.